
一、分布式发号器
在分布式系统里面我们经常需要生成整个系统的唯一ID或者叫流水号,一般生成这个唯一ID的我们俗称发号器。例如订单号、交易号等。分布式发号器是分布式系统不可或缺的基础设施之一,在保证系统的正确运行和高可用上发挥着不可取代的作用,在不同的公司有不同的实现方式。
二、UUID
UUID 是 通用唯一识别码(Universally Unique Identifier)的缩写,是一种软件建构的标准,亦为在分布式计算环境领域的一部分。目的是让分布式系统中的所有元素,都能有唯一的辨识信息,而不需要通过中央控制端来做辨识信息的指定。
JDK中也提供了UUID的实现:
java.util.UUID
或者一些第三方的工具库也会有UUID的实现可以使用。UUID虽然可以保证ID的唯一性,但是无法满足我们业务系统需要的很多特性,例如时间有序性、可逆解和可制造。UUID产生时使用了完全的时间数据,性能比较差,其长度比较长,占用的空间比较差,会简直导致数据库性能下降。更重要的是UUID并不具有有序性,会导致B+数索引在写的时候有过多的随机写操作(连续的ID会产生部分顺序写),还有就是由于在写的时候,不能产生有序的append操作,而需要进行insert操作,将读取真个B+数节点到内存,在插入一条记录会将整个节点写回磁盘,在占用空间较大的情况下,性能会明显下降。
三、基于数据库自增ID的实现方案
应该很多系统目前都是在使用数据库的自增ID,完全依赖于数据库,在对数据进行移植、扩容、洗数据、分库分表等操作时会带来很多麻烦。
如果是使用了数据库自增ID,对于分库分表最常用的一种方案就是调整自增的步长来确保跨数据库ID的唯一性。例如:分成三张表,不同的起始ID,通过调整自增步长来确保多张用户表ID的唯一性。
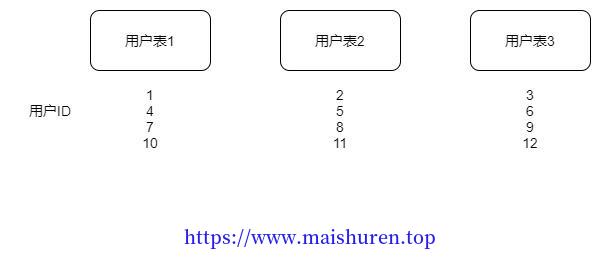
随着业务的发展,请求的量级在不断增加,导致数据库的性能瓶颈可能会出现。这种方案实现起来很简单,但是服务节点固定,自增步长也固定,如果将来增加服务服务节点或数据表,则很难在进行水平扩展。依然强依赖数据库,对数据库造成压力,因为ID的产生在一些场景下也是高频访问的服务。而且要维护多个步长管理疏散。
四、Snowflake雪花算法
Snowflake是推特开源的,在互联网公司得到了广泛的应用。但是Snowflake是Scala语言实现,文档简单,发布模式单一、缺少支持和维护,难以在显示项目中直接使用
五、分布式系统发号器的要求
5.1 全局唯一
在分布式系统中保证全局唯一的一个悲观策略就是使用锁或者说是分布式锁,只不过使用了锁会降低系统的性能。所以比较主流的方案是利用时间的有序性,并且在某个时间单元下采用自增序列,来达到全局唯一。
5.2 粗略有序
像UUID最大的问题就是无序,对于我们的业务生成的ID应该是有序的,这样我们在做核对的时候有助于我们的工作。目前主流的设计方案是:一种是秒级内有序,另外一种是毫秒级有序。在做系统设计时,我们可以通过配置的方式来决定使用哪种方式,而不是直接写死。
5.3 可反解
我们是希望系统生成的ID是带有信息量。这样在发生问题时,线上排查起来会方便很多,希望通过ID可以知道该条记录是什么时候生成的。
5.4 可制造
一个系统再高可用也不会保证永远不出问题,如果系统出问题了数据被污染,这就需要收工处理洗数据,如果使用的是数据库自增ID,ID已经被后来的业务覆盖了。系统有应该怎么恢复到出问题的时间窗口呢?所以这就需要我们的发号器一定是可以复制、可恢复、可制造的。
5.5 高性能
在使用到分布式唯一ID的系统并发量是不低的,这就要求发号器要有很高的性能。ID的生成取决于网络I/O和CPU的性能,网络I/O一般不会成功性能瓶颈。
5.6 高可用
首先,发号器必须是一个对等的集群,在一台机器挂掉之后,请求必须能转发到其他机器上,重试机制是必不可少的。同时还需要本地的容错方案,本地库的依赖方式可以作为高可用的最后一道屏障。
5.7 可伸缩
在分布式系统中,永远不能忽略业务量的增长,业务的绝对容量不是衡量系统性能的唯一标准,要知道业务永远是增长的,所以对于系统的设计不但要考虑能承受的绝对容量还需要考虑业务量增长的速度。系统的水平伸缩能否满足业务的增长速度,也是衡量系统性能的另外要给重要标准。