
一、Servlet容器的结构
Tomcat 设计了 4 种容器,分别是 Engine、Host、Context 和 Wrapper。这 4 种容器不是相互独立的关系,而是父子关系,逐层包含。如下图所示:
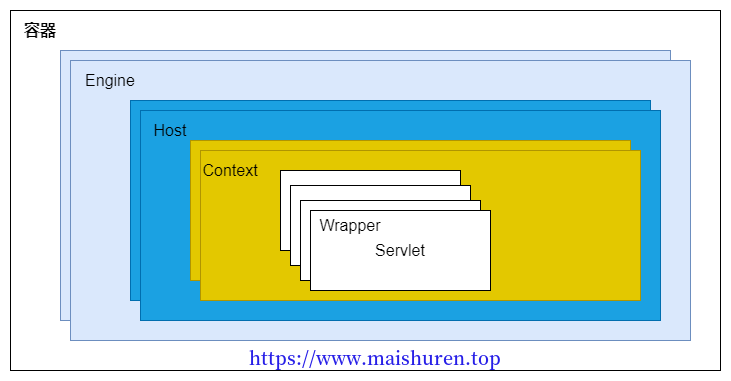
Tomcat通过这样的分层的架构设计,使得Servlet容器具有良好的灵活性。一个Service最多只能有一个Engine,Engine表示引擎,用来管理多个虚拟主机的。Host代表就是一个虚拟主机,可以给Tomcat配置多个虚拟主机,一个虚拟主机下面可以部署多个Web应用。一个Context就表示一个Web应用,Web应用中会有多个Servlet,Wrapper就表示一个Servlet。
在Tomcat的server.xml配置文件中,就体现了这样的设计,Tomcat采用组件化的设计,它的构成组件都是可以配置的。最外层的是Server。其他组件按照一定的格式要求配置在这个顶层容器中。
|
|
由于Tomcat中的这些容器是父子的包含关系,最后会形成一个树状结构,这就是设计模式中的组合模型,Tomcat就是通过组合模式来管理这些容器的。所有的容器组件都实现了Container接口,因此组合模式可以使得用户对但容器对象和组合溶剂对象的使用具有一致性。这里但容器对象是指最底层的Wrapper,组合容器对象指的是Wrapper之上的Context、Host或者Engine。
Container接口主要方法如下,在下面的接口看到了 getParent、SetParent、addChild 和 removeChild 等方法。Container 接口扩展了 LifeCycle 接口,LifeCycle 接口用来统一管理各组件的生命周期,
|
|
二、请求定位Servlet的流程
Tomcat设计了这么多个容器,在多个容器组件组合使用的时候,又是怎么的确定请求到达的是那个Wrapper容器中的Servlet来处理的?我们平时在请求Web应用时都是以URL的,例如https://www.xxx.com/user/info。其实可见每一个请求的URL都会被映射定位到一个Servlet,这就是Tomcat中Mapper组件来完成此任务的。
Mapper的工作原理:Mapper里保存了Web应用的配置信息,就是容器组件与访问路径的映射关系。例如Host容器里配置的域名、Context容器里的Web应用路径,以及Wrapper容器里Servlet映射的路径,这些配置信息就是一个多层次的Map。当一个请求到来时,Mapper组件通过解析请求的URL,再到自己保存的Map里面去找,就能定位到一个Servlet,一个URL请求最后只能定位到一个Wrapper容器,也就是Servlet。
这里画了个图来理解一下:
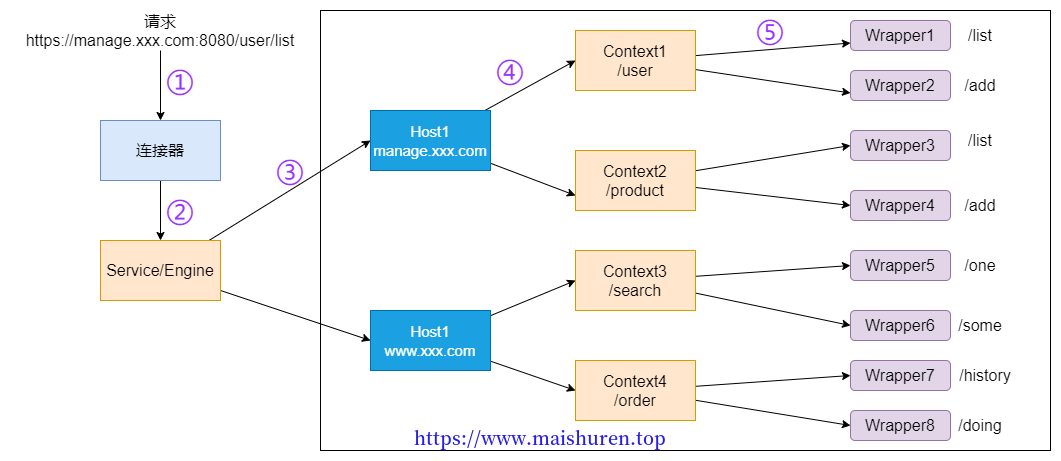
1、根据协议和端口号选定 Service 和 Engine。
我们知道 Tomcat 的每个连接器都监听不同的端口,比如 Tomcat 默认的 HTTP 连接器监听 8080 端口、默认的 AJP 连接器监听 8009 端口。上面例子中的 URL 访问的是 8080 端口,因此这个请求会被 HTTP 连接器接收,而一个连接器是属于一个 Service 组件的,这样 Service 组件就确定了。我们还知道一个 Service 组件里除了有多个连接器,还有一个容器组件,具体来说就是一个 Engine 容器,因此 Service 确定了也就意味着 Engine 也确定了。
2、根据域名选定 Host。
Service 和 Engine 确定后,Mapper 组件通过 URL 中的域名去查找相应的 Host 容器,比如例子中的 URL 访问的域名是user.shopping.com,因此 Mapper 会找到 Host2 这个容器。
3、根据 URL 路径找到 Context 组件。
Host 确定以后,Mapper 根据 URL 的路径来匹配相应的 Web 应用的路径,比如例子中访问的是 /order,因此找到了 Context4 这个 Context 容器。
4、根据 URL 路径找到 Wrapper(Servlet)。
Context 确定后,Mapper 再根据 web.xml 中配置的 Servlet 映射路径来找到具体的 Wrapper 和 Servlet。
三、Servlet定位的实现原理
并不是说只有 Servlet 才会去处理请求,实际上这个查找路径上的父子容器都会对请求做一些处理。在我写的上一篇博客(一步步带你了解Tomcat中的连接器是如何设计的),讲到连接器中的 Adapter 会调用容器的 Service 方法来执行 Servlet,最先拿到请求的是 Engine 容器,Engine 容器对请求做一些处理后,会把请求传给自己子容器 Host 继续处理,依次类推,最后这个请求会传给 Wrapper 容器,Wrapper 会调用最终的 Servlet 来处理。
上述的过程是通过使用 Pipeline-Valve 管道来实现的。Pipeline-Valve 是责任链模式,责任链模式是指在一个请求处理的过程中有很多处理者依次对请求进行处理,每个处理者负责做自己相应的处理,处理完之后将再调用下一个处理者继续处理。
Valve 表示一个处理点,比如权限认证和记录日志。接下来看看 Valve 和 Pipeline 接口中的关键方法。
Valve接口如下,Valve 是一个处理点,因此 invoke 方法就是来处理请求的。 Valve 中有 getNext 和 setNext 方法,这就很像一个链表的操作了,而且确实是一个链表将 Valve 链起来了。
|
|
Pipeline接口如下,Pipeline 中有 addValve 方法。Pipeline 中维护了一个Valve 链表,Valve 可以插入到 Pipeline 中,对请求做某些处理。Pipeline 中没有 invoke 方法,因为整个调用链的触发是 Valve 来完成的,Valve 完成自己的处理后,调用 getNext.invoke() 来触发下一个 Valve 调用。
|
|
Tomcat中每一个容器都有一个 Pipeline 对象,只要触发这个 Pipeline 的第一个 Valve,这个容器里 Pipeline 中的 Valve 就都会被调用到。不同容器的 Pipeline 通过getBasic 方法调用下层容器的Pipeline里的第一个Valve。这个 BasicValve 处于 Valve 链表的末端,它是 Pipeline 中必不可少的一个 Valve,负责调用下层容器的 Pipeline 里的第一个 Valve。如下如所示。
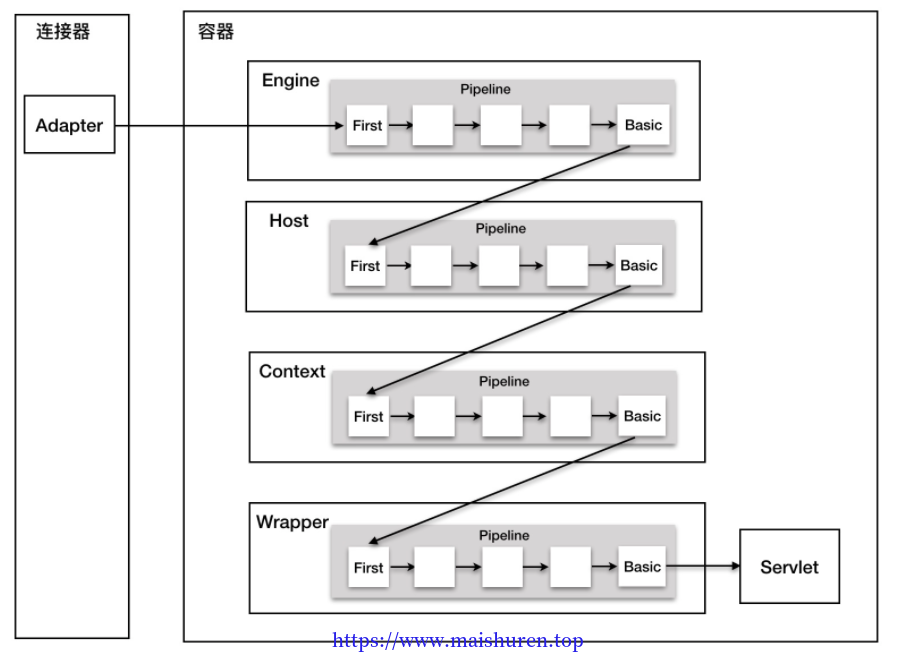
可以在整个调用过程由连接器中的 Adapter 触发的,它会调用 Engine 的第一个 Valve,例如:
|
|
Wrapper 容器的最后一个 Valve 会创建一个 Filter 链,并调用 doFilter() 方法,最终会调到 Servlet 的 service 方法。
Valve 和 Filter 的区别:
- Valve 是 Tomcat 的私有机制,与 Tomcat 的基础架构 /API 是紧耦合的。Servlet API 是公有的标准,所有的 Web 容器包括 Jetty 都支持 Filter 机制。
- 另一个重要的区别是 Valve 工作在 Web 容器级别,拦截所有应用的请求;而 Servlet Filter 工作在应用级别,只能拦截某个 Web 应用的所有请求。如果想做整个 Web 容器的拦截器,必须通过 Valve 来实现。