一、配置MySQL数据源和前置配置
1、引入依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- 引入jdbc支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- 连接MySQL数据库 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
|
2、使用MySQL作为数据源
1
2
3
4
5
6
|
spring:
datasource:
username: root
password: root123
url: jdbc:mysql://127.0.0.1:3309/test?useUnicode=true&characterEncoding=utf8&useSSL=false
driver-class-name: com.mysql.cj.jdbc.Driver
|
在使用新版本的MySQL的驱动时,使用的是这个驱动类com.mysql.cj.jdbc.Driver,有些旧的连接MySQL5.x版本的驱动com.mysql.jdbc.Driver。
SpringBoot默认是使用hikari连接池,在各个连接池中性能是最高的,当然国内很流行地使用阿里的Druid连接池。我们这里使用SpringBoot默认的hikari连接池和默认的连接池配置即可。
3、编写配置类,检测数据库连接池类型
1
2
3
4
5
6
7
8
9
10
11
|
@Configuration
@Slf4j
public class DatasourceType implements ApplicationContextAware {
@Override
public void setApplicationContext(ApplicationContext context) throws BeansException {
DataSource dataSource = context.getBean(DataSource.class);
log.info("--------------------------------------------");
log.info("using datasource {}", dataSource.getClass().getName());
log.info("--------------------------------------------");
}
}
|
上面的类中,实现了接口ApplicationContextAware,其setApplicationContext方法是可以操作Spring的上下文,因此我们可以在上下文中拿到已经被注入的数据源,从而在日志中打印出来。其中@Slf4j注解是引入的依赖lombok中的功能,关于lombok可以去了解一下,这里不讲述。
4、常见一个测试表student学生表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for student
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `t_student` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`gender` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`age` int NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
|
5、创建实体类
1
2
3
4
5
6
7
8
|
@Data
public class Student {
private Long id;
private String name;
private String gender;
private Integer age;
}
|
6、编写SpringBoot启动类
1
2
3
4
5
6
7
|
@SpringBootApplication
public class JdbcApplication {
public static void main(String[] args) {
SpringApplication.run(JdbcApplication.class, args);
}
}
|
二、使用JdbcTemplate操作MySQL数据库
在刚开始学习Spring的时候,我们操作数据库都原生的JDBC来进行操作,那些步骤会很麻烦,查询之后的结果处理也是很繁琐,更别说事务处理了。Spring中封装了JDBC成JdbcTemplate,一些常用的操作都可以通过JdbcTemplate来进行操作。在Spring中也有其他的一些Template例如封装了Http客户端的RestTemplate。这也体现了SpringBoot的理念— 尽量减少程序员的配置,好了接下来直接使用JdbcTemplate了。
1、编写服务结果接口
1
2
3
4
5
6
7
8
9
10
11
12
|
public interface IStudentService {
Student findStudentById(Long id);
List<Student> findUsers(String name);
int insertStudent(Student student);
int updateStudent(Student student);
int deleteStudent(Long id);
}
|
2、IStudentService实现类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
@Service
public class StudentServiceImpl implements IStudentService {
@Autowired
private JdbcTemplate jdbcTemplate;
/**
* 拿到映射关系
*
* @return
*/
private RowMapper<Student> getStudentMapper() {
return (resultSet, i) -> {
Student student = new Student();
student.setId(resultSet.getLong("id"));
student.setName(resultSet.getString("name"));
student.setAge(resultSet.getInt("age"));
student.setGender(resultSet.getString("gender"));
return student;
};
}
@Override
public Student findStudentById(Long id) {
String sql = "select id,name,gender,age from t_student where id = ?";
Object[] param = new Object[]{id};
return jdbcTemplate.queryForObject(sql, param, getStudentMapper());
}
@Override
public List<Student> findUsers(String name) {
String sql = "select id,name,gender,age from t_student " +
"where name like concat('%',?,'%')";
Object[] param = new Object[]{name};
return jdbcTemplate.query(sql, param, getStudentMapper());
}
@Override
public int insertStudent(Student student) {
String sql = "insert into t_student(name,gender,age) value(?,?,?)";
return jdbcTemplate.update(sql, student.getName(), student.getGender(), student.getAge());
}
@Override
public int updateStudent(Student student) {
String sql = "update t_student set name=?,gender=?,age=? where id=?";
return jdbcTemplate.update(sql, student.getName(), student.getGender(), student.getAge(), student.getId());
}
@Override
public int deleteStudent(Long id) {
String sql = "delete from t_student where id = ?";
return jdbcTemplate.update(sql, id);
}
}
|
对于JdbcTemplate的映射关系是需要开发者自己区实现RowMapper接口,这样就可以完成数据表到实体类的关系映射。上述中对于RowMapper使用了Lambda表达式,最低需要Java8及以上的版本。
上述代码中实现了对于student表的CRUD即增删查改,写好sql之后,只需要传递参数即可,JdbcTemplate就会执行sql操作数据库,返回操作结果。
3、编写单元测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
@RunWith(SpringRunner.class)
@SpringBootTest
public class TestApplication {
@Autowired
private IStudentService studentService;
@Test
public void test1() {
Student student = new Student();
student.setName("tom");
student.setGender("男");
student.setAge(18);
studentService.insertStudent(student);
student.setAge(20);
studentService.insertStudent(student);
student.setAge(22);
studentService.insertStudent(student);
}
@Test
public void test2() {
Student student = studentService.findStudentById(1L);
System.out.println(student.toString());
List<Student> all = studentService.findAll();
all.forEach(e -> System.out.println(e.toString()));
}
@Test
public void test3() {
Student student = new Student();
student.setId(1L);
student.setName("jack");
student.setGender("男");
student.setAge(18);
studentService.updateStudent(student);
Student db = studentService.findStudentById(1L);
System.out.println(db.toString());
}
@Test
public void test4() {
List<Student> tom = studentService.findUsers("tom");
tom.forEach(e -> System.out.println(e.toString()));
}
@Test
public void test5() {
studentService.deleteStudent(3L);
List<Student> all = studentService.findAll();
all.forEach(student -> System.out.println(student.toString()));
}
}
|
在上面的test3方法中,会执行两条sql,是由下面这两个方法发起的。在表面上看这两条sql实在同一个方法内执行,但是这两条sql是使用不同的数据库连接完成的。当JdbcTemplate执行下面的update方法时,会从数据库连接池中获取一个连接执行sql,执行完毕之后会关闭数据库连接。当执行到queryForObject,又会从数据库连接池中获取一个连接执行sql。
很明显这样的操作是很浪费资源的,这样我们肯定是希望一个数据库连接内执行多条sql。我们可以使用StatementCallback或者ConnectionCallback接口实现回调。
1
2
|
jdbcTemplate.update(sql, student.getName(), student.getGender(), student.getAge(), student.getId());
jdbcTemplate.queryForObject(sql, param, getStudentMapper());
|
使用StatementCallback实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
public Student findStudentById2(Long id) {
return jdbcTemplate.execute(new StatementCallback<Student>() {
@Override
public Student doInStatement(Statement statement) throws SQLException, DataAccessException {
String sql1 = "select count(*) total from t_student where id = " + id;
ResultSet resultSet1 = statement.executeQuery(sql1);
while (resultSet1.next()) {
int total = resultSet1.getInt("total");
log.info("total:{}", total);
}
String sql2 = "select id,name,gender,age from t_student where id = " + id;
ResultSet resultSet2 = statement.executeQuery(sql2);
Student student = new Student();
while (resultSet2.next()) {
int row = resultSet2.getRow();
student = getStudentMapper().mapRow(resultSet2, row);
}
return student;
}
});
}
|
使用ConnectionCallback实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
public Student findStudentById3(Long id) {
return jdbcTemplate.execute(new ConnectionCallback<Student>() {
@Override
public Student doInConnection(Connection connection) throws SQLException, DataAccessException {
String sql1 = "select count(*) total from t_student where id = ?";
PreparedStatement statement1 = connection.prepareStatement(sql1);
statement1.setLong(1, id);
ResultSet resultSet1 = statement1.executeQuery();
while (resultSet1.next()) {
int total = resultSet1.getInt("total");
log.info("total:{}", total);
}
String sql2 = "select id,name,gender,age from t_student where id = ?";
PreparedStatement statement2 = connection.prepareStatement(sql2);
statement2.setLong(1, id);
ResultSet resultSet2 = statement2.executeQuery();
Student student = new Student();
while (resultSet2.next()) {
int row = resultSet2.getRow();
student = getStudentMapper().mapRow(resultSet2, row);
}
return student;
}
});
}
|
三、使用JPA操作数据库
JPA (Java Persistence API) Java持久化API。是一套Java官方制定的ORM 方案。ORM(Object Relational Mapping)对象关系映射,在操作数据库之前,先把数据表与实体类关联起来。然后通过实体类的对象操作(增删改查)数据库表;所以说,ORM是一种实现使用对象操作数据库的设计思想。目前主流的ORM框架有Hibernate (JBoos)、EclipseTop(Eclipse社区)、OpenJPA (Apache基金会)、Hibernate是众多实现者之中,性能最好的。
Spring社区整合Hibernate在这上面做了增强,JPA就是依靠Hibernate实现的。使用JPA的开发人员操作实体类即可,不需要编写sql,它是通过一个持久化上下文(Persistence Context)来使用的。该上下文包含这三部分:
- 对象关系映射(ORM)描述,JPA支持注解或XML两种形式的描述,在Spring Boot中主要通过注解实现。
- 实体操作API,实现对实体对象的CRUD操作,来完成对象的持久化和查询。
- 查询语言,约定了面向对象的查询语言JPQL(Java Persistent Query Language),通过这层关系可以实现比较灵活的查询。
3.1 MySQL数据源和JPA的配置
1
2
3
4
5
6
7
8
9
10
11
12
13
|
spring:
datasource:
username: root
password: root123
url: jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false
driver-class-name: com.mysql.cj.jdbc.Driver
jpa:
show-sql: true
hibernate:
ddl-auto: update
naming:
# 驼峰命名映射
physical-strategy: org.springframework.boot.orm.jpa.hibernate.SpringPhysicalNamingStrategy
|
spring.jpa.show-sql=true在使用JPA执行sql时,把sql输出到日志显示。spring.jpa.hibernate.ddl-auto=update该配置项是当实体类对应的表不存在时,会自动创建表,存在则不会。
none:禁止DDL处理
validate:验证架构,不对数据库做任何更改
update:表不存在时创建
create:每次启动都会删除表,然后重新创建
create-drop:每次会话结束之后,就删除表
spring.jpa.naming就是关于实体类命名和数据库字段的映射处理。有physical-strategy和implicit-strategy。
- 第一步:如果我们没有使用@Table或@Column指定了表或字段的名称,则由SpringImplicitNamingStrategy为我们隐式处理,表名隐式处理为类名,列名隐式处理为字段名。如果指定了表名列名,SpringImplicitNamingStrategy不起作用。
- 第二步:将上面处理过的逻辑名称解析成物理名称。无论在实体中是否显示指定表名列名,SpringPhysicalNamingStrategy都会被调用。
所以如果我们想要自定义命名策略,可以根据自己的需求选择继承二者,并在配置文件中通过spring.jpa.hibernate.naming.implicit-strategy 或 spring.jpa.hibernate.naming.physical-strategy 进行指定自己的策略(例如为表名添加指定前缀)。
3.2 JPA开发实战
1、编写实体类
1
2
3
4
5
6
7
8
9
10
11
12
|
@Data
@Entity
@Table(name = "t_student")
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@Convert(converter = SexConverter.class)
private SexEnum gender;
private Integer age;
}
|
@Data在编译时生成getter、setter和toString方法。@Entity声明该类是个实体类。@Table(name = "t_student")声明该类关联的数据表。@Id声明主键,@GeneratedValue(strategy = GenerationType.IDENTITY)声明主键的生成策略是使用数据库自增Id。
性别枚举类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
@Getter
public enum GenderEnum {
/**
* 1为男
*/
MALE(1,"男"),
/**
* 2为女
*/
FEMALE(2,"女");
private Integer id;
private String name;
GenderEnum(Integer id, String name) {
this.id = id;
this.name = name;
}
public static GenderEnum getSexById(int id){
for (GenderEnum genderEnum : GenderEnum.values()) {
if (genderEnum.getId()==id){
return genderEnum;
}
}
return null;
}
}
|
自定义的性别转换器
1
2
3
4
5
6
7
8
9
10
11
|
public class GengerConverter implements AttributeConverter<GenderEnum, Integer> {
@Override
public Integer convertToDatabaseColumn(GenderEnum genderEnum) {
return genderEnum.getId();
}
@Override
public GenderEnum convertToEntityAttribute(Integer id) {
return GenderEnum.getSexById(id);
}
}
|
2、定义JPA接口
Repository是Spring Data项目的顶层接口,它并没有定义方法,其子接口CrudRepository定了实体基本的增删查改的方法,功能性还不足够强大,PagingAndSortingRepository对CrudRepository的功能进行扩展并且提供了分页和排序的功能,最后JpaRepository同时集成了PagingAndSortingRepository和QueryByExampleExecutor,拥有了按照例子查询的功能。一般我们开发只需要扩展JpaRepository接口即可。
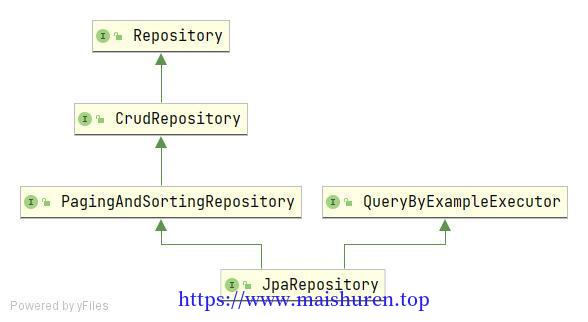
定义操作Student实体类的接口,只需要继承JpaRepository即可。这样我们就可以使用Spring Data Jpa帮我实现的方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
@Repository
public interface StudentRepository extends JpaRepository<Student, Long> {
/**
* 命名查询:通过name属性模糊查询
*
* @param name 学生名字
* @return 查询结果
*/
List<Student> findByNameLike(String name);
/**
* jql语言查询
* @param name
* @return
*/
@Query("from Student where name like concat('%',?1,'%')")
List<Student> getUsers(String name);
}
|
3、编写业务方法
IStudentService接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public interface IStudentService {
Student findStudentById(Long id);
List<Student> findUsers(String name);
Student insertStudent(Student student);
Student updateStudent(Student student);
void deleteStudent(Long id);
List<Student> findAll();
}
|
IStudentService实现类StudentServiceImpl
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
@Service
public class StudentServiceImpl implements IStudentService {
@Autowired
private StudentRepository studentRepository;
@Override
public Student findStudentById(Long id) {
return studentRepository.getOne(id);
}
@Override
public List<Student> findUsers(String name) {
return studentRepository.findByNameLike(name);
}
@Transactional(rollbackFor = RuntimeException.class)
@Override
public Student insertStudent(Student student) {
return studentRepository.save(student);
}
@Transactional(rollbackFor = RuntimeException.class)
@Override
public Student updateStudent(Student student) {
return studentRepository.save(student);
}
@Transactional(rollbackFor = RuntimeException.class)
@Override
public void deleteStudent(Long id) {
studentRepository.deleteById(id);
}
@Override
public List<Student> findAll() {
return studentRepository.findAll();
}
}
|
上面的代码中,通过Jap来操作数据十分简单,很多基本的CRUD都已经实现了,只需要传参进去即可。通过注解进行事务管理@Transactional(rollbackFor = RuntimeException.class),在执行多个sql时,只会在一个数据库连接内进行,避免了像使用JdbcTemplate的缺点。
3.3 使用JPA语言
1
2
3
4
5
6
7
|
/**
* jql语言查询
* @param name
* @return
*/
@Query("from Student where name like concat('%',?1,'%')")
List<Student> getUsers(String name);
|
使用JQL语言是要主要,主要操作的是实体类以及其属性,并不会去操作表。当然要使用原生的sql查询也可以,在@Query里面添加一个属性nativeQuery=true即可。
3.4 使用命名查询
1
2
3
4
5
6
7
|
/**
* 命名查询:通过name属性模糊查询
*
* @param name 学生名字
* @return 查询结果
*/
List<Student> findByNameLike(String name);
|
命名查询的动词是find/get开始,by标识通过实体类的哪一个属性作为条件,Like是对这个属性进行模糊查询,类型还有升降序之类的。多个属性条件之间可以使用And或者Or逻辑处理。JPA会自动帮我们生成对应的sql语句。
四、总结
关于SpringBoot操作数据的入门就介绍到这里,关于更多的高级操作可能后续再做讲解。