1.通用的设计方法
在应对高并发大流量时也会采用类似“抵御洪水”的方案,归纳起来共有三种方法:
- Scale-out(横向扩展):分而治之是一种常见的高并发系统设计方法,采用分布式部署的方式把流量分流开,让每个服务器都承担一部分并发和流量。
- 缓存:使用缓存来提高系统的性能,就好比用“拓宽河道”的方式抵抗高并发大流量的冲击。
- 异步:在某些场景下,未处理完成之前,我们可以让请求先返回,在数据准备好之后再通知请求方,这样可以在单位时间内处理更多的请求。
2.Scale-up vs Scale-out
在高并发系统设计上也沿用了同样的思路,将类似追逐摩尔定律不断提升 CPU 性能的方案叫做 Scale-up(纵向扩展),把类似 CPU 多核心的方案叫做 Scale-out,这两种思路在实现方式上是完全不同的。
- Scale-up,通过购买性能更好的硬件来提升系统的并发处理能力,比方说目前系统 4 核 4G 每秒可以处理 200 次请求,那么如果要处理 400 次请求呢?很简单,我们把机器的硬件提升到 8 核 8G(硬件资源的提升可能不是线性的,这里仅为参考)。
- Scale-out,则是另外一个思路,它通过将多个低性能的机器组成一个分布式集群来共同抵御高并发流量的冲击。沿用刚刚的例子,我们可以使用两台 4 核 4G 的机器来处理那 400 次请求。
2.1如何抉择Scale-up 和 Scale-out?
在系统设计初期会考虑使用 Scale-up 的方式,因为这种方案足够简单,所谓能用堆砌硬件解决的问题就用硬件来解决,但是当系统并发超过了单机的极限时,我们就要使用 Scale-out 的方式。
Scale-out 虽然能够突破单机的限制,但也会引入一些复杂问题。比如,如果某个节点出现故障如何保证整体可用性?当多个节点有状态需要同步时,如何保证状态信息在不同节点的一致性?如何做到使用方无感知的增加和删除节点?等等。
3.使用缓存提升性能
缓存遍布在系统设计的每个角落,从操作系统到浏览器,从数据库到消息队列,任何略微复杂的服务和组件中,你都可以看到缓存的影子。我们使用缓存的主要作用是提升系统的访问性能,那么在高并发的场景下,就可以支撑更多用户的同时访问。
普通磁盘的寻道时间是 10ms 左右,而相比于磁盘寻道花费的时间,CPU 执行指令和内存寻址的时间都在是纳秒级别,从千兆网卡上读取数据的时间是在微秒级别。所以在整个计算机体系中,磁盘是最慢的一环,甚至比其它的组件要慢几个数量级。因此,我们通常使用以内存作为存储介质的缓存,以此提升性能。
将任何降低响应时间的中间存储都称为缓存。缓存的思想遍布很多设计领域,比如在操作系统中 CPU 有多级缓存,文件有 Page Cache 缓存等。
4.异步处理
异步也是一种常见的高并发设计方法,在很多文章中都能听到这个名词,与之共同出现的还有它的反义词:同步。比如,分布式服务框架 Dubbo 中有同步方法调用和异步方法调用,IO 模型中有同步 IO 和异步 IO。
同步调用代表调用方要阻塞等待被调用方法中的逻辑执行完成。这种方式下,当被调用方法响应时间较长时,会造成调用方长久的阻塞,在高并发下会造成整体系统性能下降甚至发生雪崩。
异步调用恰恰相反,调用方不需要等待方法逻辑执行完成就可以返回执行其他的逻辑,在被调用方法执行完毕后再通过回调、事件通知等方式将结果反馈给调用方。
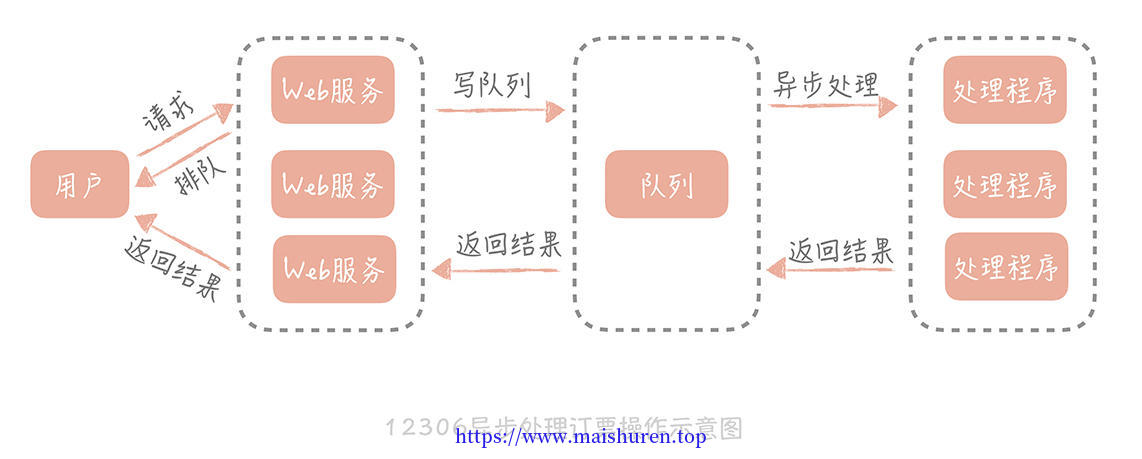
异步调用在大规模高并发系统中被大量使用,**比如我们熟知的 12306 网站。**当我们订票时,页面会显示系统正在排队,这个提示就代表着系统在异步处理我们的订票请求。在 12306 系统中查询余票、下单和更改余票状态都是比较耗时的操作,可能涉及多个内部系统的互相调用,如果是同步调用就会像 12306 刚刚上线时那样,高峰期永远不可能下单成功。
而采用异步的方式,后端处理时会把请求丢到消息队列中,同时快速响应用户,告诉用户我们正在排队处理,然后释放出资源来处理更多的请求。订票请求处理完之后,再通知用户订票成功或者失败。
处理逻辑后移到异步处理程序中,Web 服务的压力小了,资源占用的少了,自然就能接收更多的用户订票请求,系统承受高并发的能力也就提升了。
5.总结
高并发系统的演进应该是循序渐进,以解决系统中存在的问题为目的和驱动力的。