Hadoop是什么?
1)hadoop是由Apache基金会所开发的分布式系统基础架构
2)主要解决海量数据的存储和海量数据的分析计算问题
3)广义来说,hadoop通常是之一个更广泛的概念—hadoop生态圈

Hadoop三大发行版本
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
Apache版本最原始(最基础)的版本,对于入门学习最好。
Cloudera在大型互联网企业中用的较多。
Hortonworks文档较好。
- Apache Hadoop
官网地址:http://hadoop.apache.org/releases.html
下载地址:https://archive.apache.org/dist/hadoop/common/
- Cloudera Hadoop
官网地址:https://www.cloudera.com/downloads/cdh/5-10-0.html
下载地址:http://archive-primary.cloudera.com/cdh5/cdh/5/
(1)2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
(2)2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
(3)CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。
(4)Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对Hadoop的技术支持。
(5)Cloudera的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大数据的Impala项目。
- Hortonworks Hadoop
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform
(1)2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
(2)公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
(3)雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks的首席执行官。
(4)Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
(5)HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook开源的Hive中。Hortonworks的Stinger开创性的极大的优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。
(6)Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Window Server和Windows Azure在内的Microsoft Windows平台上本地运行。定价以集群为基础,每10个节点每年为12500美元。
Hadoop的组成
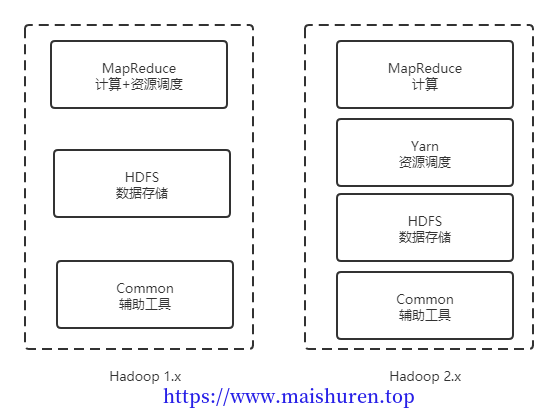
HDFS架构概述
HDFS由NameNode、DataNode、SencodaryNode组成。
- NameNode:存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
- DataNode:在本地文件系统存储文件块数据,以及块数据的校验和。
- SecondaryNode:用于监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
Yarn架构概述
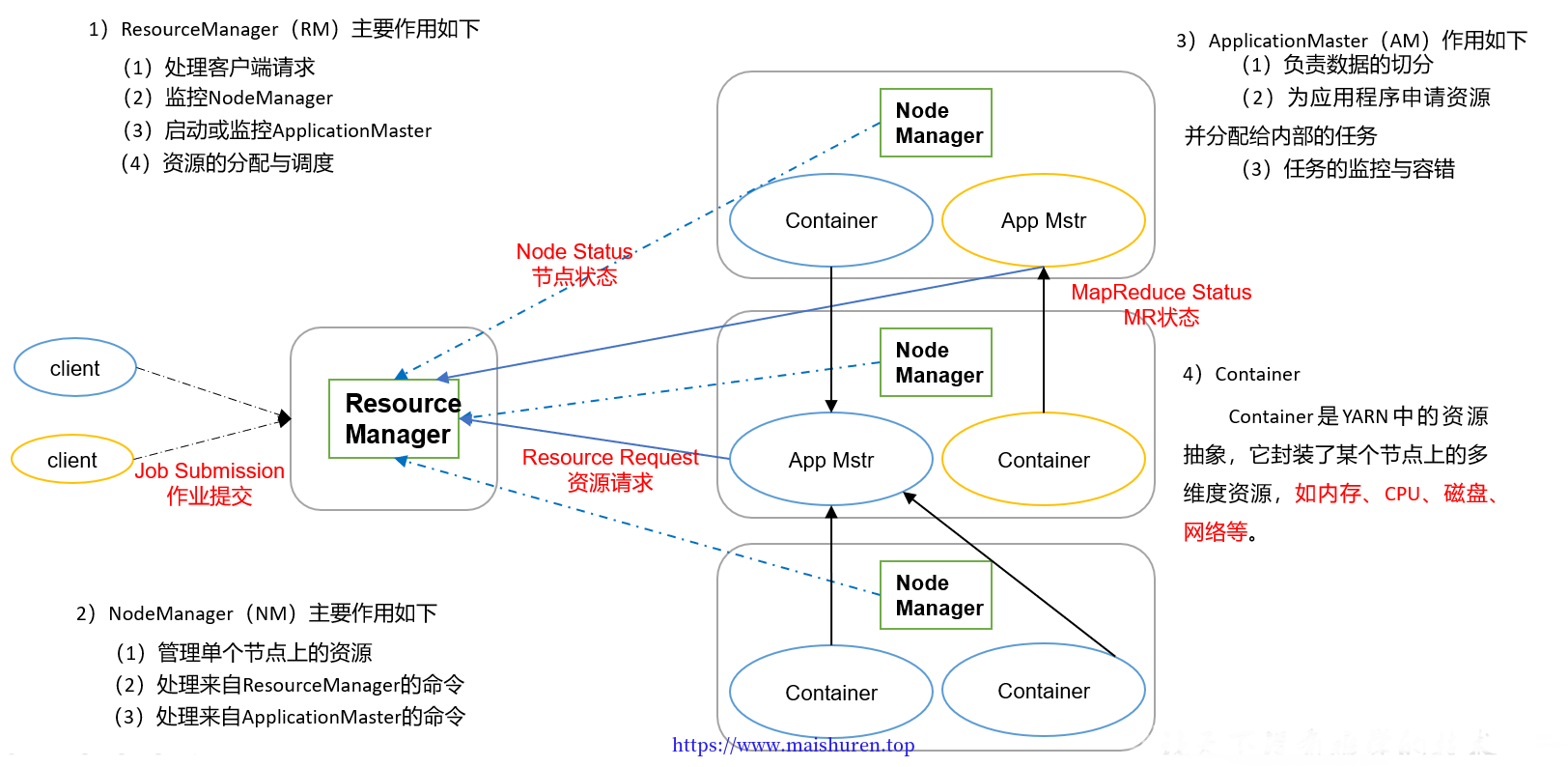
MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
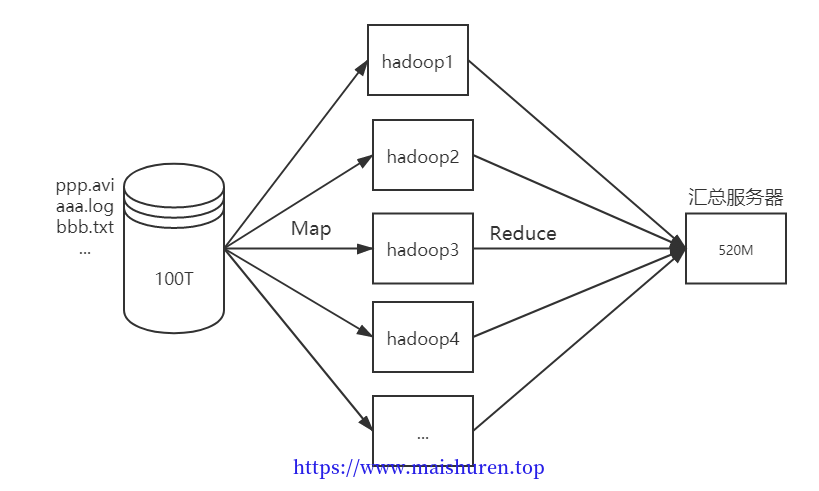
大数据生态体系
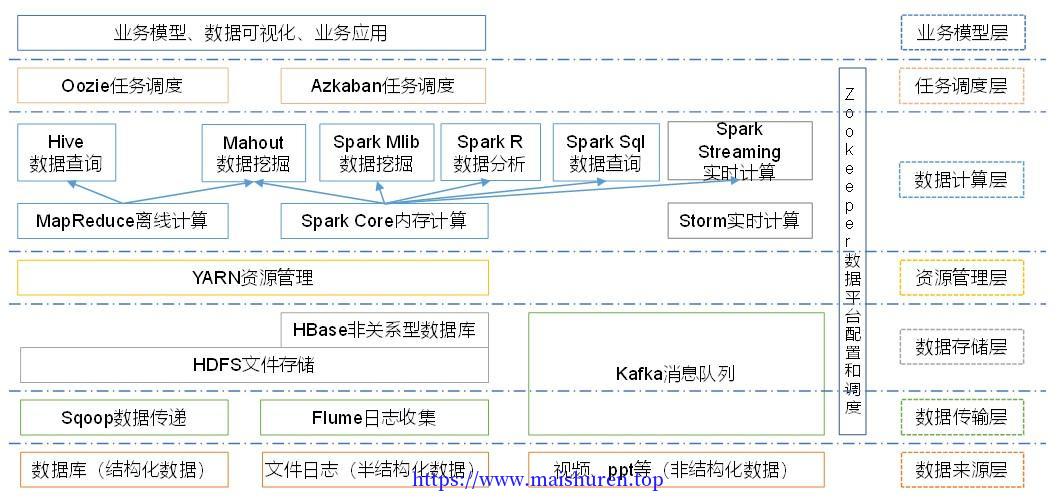
1)Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
2)Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
(1)通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
(2)高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
(3)支持通过Kafka服务器和消费机集群来分区消息。
(4)支持Hadoop并行数据加载。
4)Storm:Storm用于“连续计算”,对数据流做连续查询,在计算时就将结果以流的形式输出给用户。
5)Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
6)Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
7)Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
8)Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
10)R语言:R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
11)Mahout:Apache Mahout是个可扩展的机器学习和数据挖掘库。
12)ZooKeeper:Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、 分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
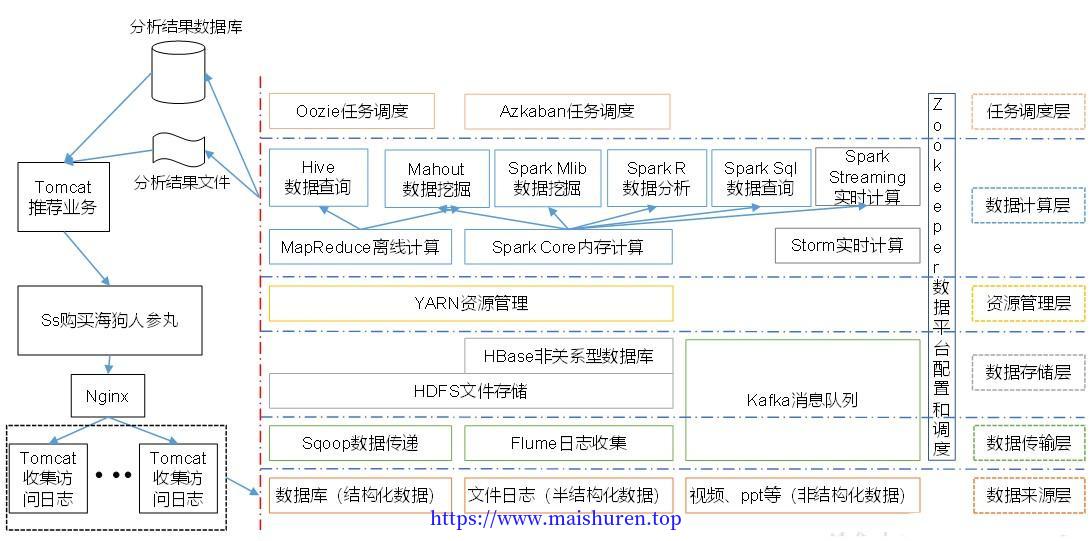
推荐系统框架图
Hadoop运行环境搭建
安装JDK和安装Hadoop
在根目录的opt目录下新建software目录,再在software目录下新建bigdata目录,hadoop和jdk的压缩包都放在bigdata目录下。
1.解压jdk压缩包
1
|
tar -zxvf jdk-8u211-linux-x64.tar.gz
|
2.解压Hadoop压缩包
1
|
tar -zxvf hadoop-2.7.2.tar.gz
|
3.配置环境变量
1
2
3
4
5
|
export JAVA_HOME=/opt/software/bigdata/jdk1.8
export JRE_HOME=/opt/software/bigdata/jdk1.8/jre
export HADOOP_HOME=/opt/software/bigdata/hadoop
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
|
4.验证环境变量
1
2
3
4
5
6
7
8
9
10
11
12
|
[root@centos7 hadoop]# java -version
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
[root@centos7 hadoop]# hadoop version
Hadoop 2.7.2
Subversion Unknown -r Unknown
Compiled by root on 2017-05-22T10:49Z
Compiled with protoc 2.5.0
From source with checksum d0fda26633fa762bff87ec759ebe689c
This command was run using /opt/software/bigdata/hadoop/share/hadoop/common/hadoop-common-2.7.2.jar
|
配置成功!
Hadoop目录结构
1、查看Hadoop目录结构
1
2
3
4
5
6
7
8
9
10
11
12
|
[root@hadoop101 hadoop-2.7.2]$ ll
总用量 52
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 **bin**
drwxr-xr-x. 3 atguigu atguigu 4096 5月 22 2017 **etc**
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 include
drwxr-xr-x. 3 atguigu atguigu 4096 5月 22 2017 **lib**
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 libexec
-rw-r--r--. 1 atguigu atguigu 15429 5月 22 2017 LICENSE.txt
-rw-r--r--. 1 atguigu atguigu 101 5月 22 2017 NOTICE.txt
-rw-r--r--. 1 atguigu atguigu 1366 5月 22 2017 README.txt
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 **sbin**
drwxr-xr-x. 4 atguigu atguigu 4096 5月 22 2017 **share**
|
2、重要目录
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
Hadoop运行模式
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
Hadoop官方网站:http://hadoop.apache.org/
本地运行模式
官方Grep案例
- 创建在hadoop-2.7.2文件下面创建一个input文件夹
1
|
[root@centos7 hadoop]$ mkdir input
|
- 将Hadoop的xml配置文件复制到input
1
|
[root@centos7 hadoop]$ cp etc/hadoop/*.xml input
|
- 执行share目录下的MapReduce程序
1
|
[root@centos7 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
|
- 查看输出结果
1
|
[root@centos7 hadoop]$ cat output/*
|
官方WordCount程序
- 创建在hadoop文件下面创建一个wcinput文件夹
1
|
[root@centos7 hadoop]$ mkdir wcinput
|
- 在wcinput文件下创建一个wc.input文件
1
2
3
|
[root@centos7 hadoop]$ cd wcinput
[root@centos7 hadoop]$ touch wc.input
|
- 编辑wc.input文件
1
2
3
4
5
6
|
[root@centos7 hadoop]$ vim wc.input
hadoop yarn
hadoop mapreduce
root
root
|
- 回到Hadoop目录,执行程序
1
|
[root@centos7 hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
|
- 查看结果
1
2
3
4
5
6
|
[root@centos7 hadoop]$ cat wcoutput/part-r-00000
root 2
hadoop 2
mapreduce 1
yarn 1
|
伪分布式运行模式
启动HDFS并运行MapReduce程序
- 分析
(1)配置集群
(2)启动、测试集群增、删、查
(3)执行WordCount案例
- 执行步骤
(1)配置集群
(a)配置:hadoop-env.sh
Linux系统中获取JDK的安装路径:
1
2
3
|
[root@centos7 ~]# echo $JAVA_HOME
/opt/module/jdk1.8.0_211
|
修改hadoop-env.sh中的JAVA_HOME 路径:
1
|
export JAVA_HOME=/opt/module/jdk1.8.0_211
|
(b)配置:core-site.xml
1
2
3
4
5
6
7
8
9
10
|
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/data/tmp</value>
</property>
|
(c)配置:hdfs-site.xml
1
2
3
4
5
|
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
|
(2)启动集群
(a)格式化NameNode(第一次启动时格式化,以后就不要总格式化)
1
|
[root@centos7 hadoop]$ bin/hdfs namenode -format
|
(b)启动NameNode
1
|
[root@centos7 hadoop]$ sbin/hadoop-daemon.sh start namenode
|
(c)启动DataNode
1
|
[root@centos7 hadoop]$ sbin/hadoop-daemon.sh start datanode
|
(3)查看集群
(a)查看是否启动成功
1
2
3
4
5
|
[root@centos7 hadoop]$ jps
13586 NameNode
13668 DataNode
13786 Jps
|
(b)web端查看HDFS文件系统
1
|
http://ip:50070/dfshealth.html#tab-overview
|
(c)查看产生的Log日志
说明:在企业中遇到Bug时,经常根据日志提示信息去分析问题、解决Bug。
当前目录:hadoop/logs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
[root@centos7 logs]$ ls
hadoop-root-datanode-hadoop.root.com.log
hadoop-root-datanode-hadoop.root.com.out
hadoop-root-namenode-hadoop.root.com.log
hadoop-root-namenode-hadoop.root.com.out
SecurityAuth-root.audit
[root@centos7 logs]$ cat hadoop-root-datanode-hadoop101.log
[root@centos7 hadoop]$ cd data/tmp/dfs/name/current/
[root@centos7 current]$ cat VERSION
**clusterID=CID-f0330a58-36fa-4a2a-a65f-2688269b5837**
[root@centos7 hadoop]$ cd data/tmp/dfs/data/current/
**clusterID=CID-f0330a58-36fa-4a2a-a65f-2688269b5837**
|
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。
(4)操作集群
(a)在HDFS文件系统上创建一个input文件夹
1
|
[root@centos7 hadoop]$ bin/hdfs dfs -mkdir -p /user/atguigu/input
|
(b)将测试文件内容上传到文件系统上
1
2
3
|
[root@centos7 hadoop]$bin/hdfs dfs -put wcinput/wc.input
/user/root/input/
|
(c)查看上传的文件是否正确
1
2
3
|
[root@centos7 hadoop]$ bin/hdfs dfs -ls /user/atguigu/input/
[root@centos7 hadoop]$ bin/hdfs dfs -cat /user/atguigu/ input/wc.input
|
(d)运行MapReduce程序
1
|
[root@centos7 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/root/input/ /user/root/output
|
(e)查看输出结果
1
|
[root@centos7 hadoop]$ bin/hdfs dfs -cat /user/root/output/*
|
浏览器查看,如图所示 查看output文件
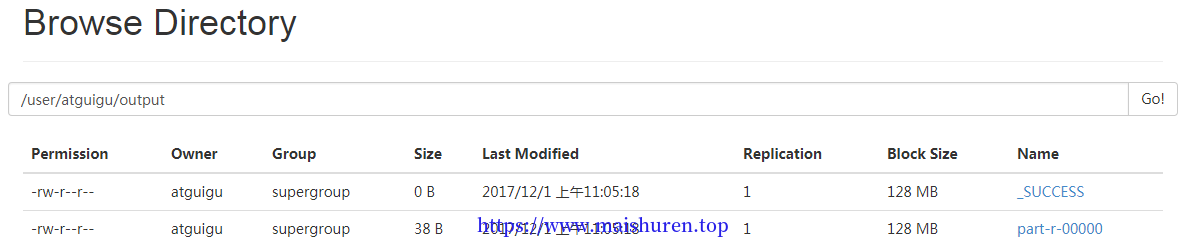
(f)将测试文件内容下载到本地
1
|
[root@centos7 hadoop]$ hdfs dfs -get /user/atguigu/output/part-r-00000 ./wcoutput/
|
(g)删除输出结果
1
|
[root@centos7 hadoop]$ hdfs dfs -rm -r /user/atguigu/output
|
启动YARN并运行MapReduce程序
- 分析
(1)配置集群在YARN上运行MR
(2)启动、测试集群增、删、查
(3)在YARN上执行WordCount案例
- 执行步骤
(1)配置集群
(a)配置yarn-env.sh.配置一下JAVA_HOME
1
|
export JAVA_HOME=/opt/module/jdk1.8.0_211
|
(b)配置yarn-site.xml
1
2
3
4
5
6
7
8
9
10
|
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
|
(c)配置:mapred-env.sh.配置一下JAVA_HOME
1
|
export JAVA_HOME=/opt/module/jdk1.8.0_144
|
(d)配置: (对mapred-site.xml.template重新命名为) mapred-site.xml
1
2
|
[root@centos7 hadoop]$ mv mapred-site.xml.template mapred-site.xml
[root@centos7 hadoop]$ vim mapred-site.xml
|
1
2
3
4
5
|
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
|
(2)启动集群
(a)启动前必须保证NameNode和DataNode已经启动
(b)启动ResourceManager
1
|
[root@centos7 hadoop]$ sbin/yarn-daemon.sh start resourcemanager
|
(c)启动NodeManager
1
|
[root@centos7 hadoop]$ sbin/yarn-daemon.sh start nodemanager
|
(3)集群操作
(a)YARN的浏览器页面查看,如图所示
YARN的浏览器页面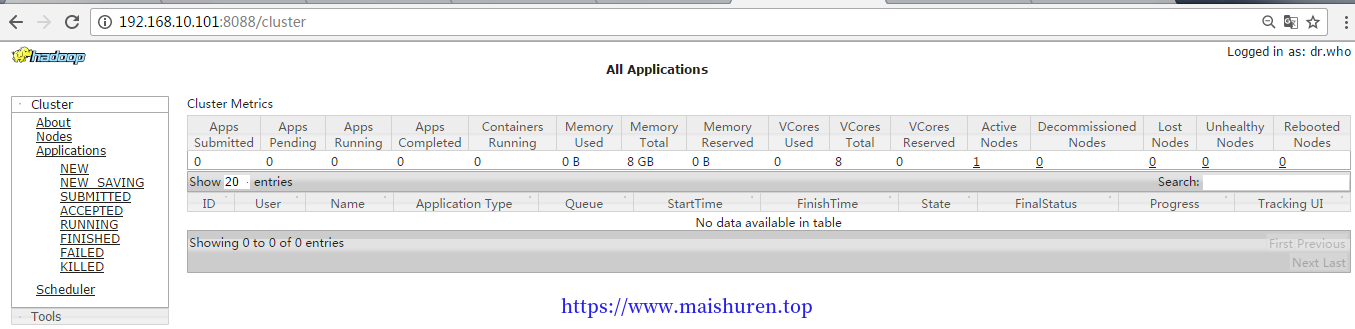
(b)删除文件系统上的output文件
1
|
[root@centos7 hadoop]$ bin/hdfs dfs -rm -R /user/atguigu/output
|
(c)执行MapReduce程序
1
|
[root@centos7 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input /user/atguigu/output
|
(d)查看运行结果,如图所示
1
|
[root@centos7 hadoop]$ bin/hdfs dfs -cat /user/atguigu/output/*
|

配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
- 配置mapred-site.xml
1
|
[root@centos7 hadoop]$ vim mapred-site.xml
|
在该文件里面增加如下配置。
1
2
3
4
5
6
7
8
9
10
11
|
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop101:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop101:19888</value>
</property>
|
- 启动历史服务器
1
|
[root@centos7 hadoop]$ sbin/mr-jobhistory-daemon.sh start historyserver
|
- 查看历史服务器是否启动
1
|
[root@centos7 hadoop]$jps
|
- 查看JobHistory:http://ip:19888/jobgistory
配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
开启日志聚集功能具体步骤如下:
- 配置yarn-site.xml
1
|
[root@centos7 hadoop]$ vi yarn-site.xml
|
在该文件里面增加如下配置。
1
2
3
4
5
6
7
8
9
10
11
|
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
|
- 关闭NodeManager 、ResourceManager和HistoryServer
1
2
3
4
5
|
[root@centos7 hadoop]$ sbin/yarn-daemon.sh stop resourcemanager
[root@centos7 hadoop]$ sbin/yarn-daemon.sh stop nodemanager
[root@centos7 hadoop]$ sbin/mr-jobhistory-daemon.sh stop historyserver
|
- 启动NodeManager 、ResourceManager和HistoryServer
1
2
3
4
5
|
[root@centos7 hadoop]$]$ sbin/yarn-daemon.sh start resourcemanager
[root@centos7 hadoop]$ sbin/yarn-daemon.sh start nodemanager
[root@centos7 hadoop]$ sbin/mr-jobhistory-daemon.sh start historyserver
|
- 删除HDFS上已经存在的输出文件
1
|
[root@centos7 hadoop]$ bin/hdfs dfs -rm -R /user/atguigu/output
|
- 执行WordCount程序
1
|
[root@centos7 hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/atguigu/input /user/atguigu/output
|
- 查看日志,如图所示
http://hadoop101:19888/jobhistory
Job History
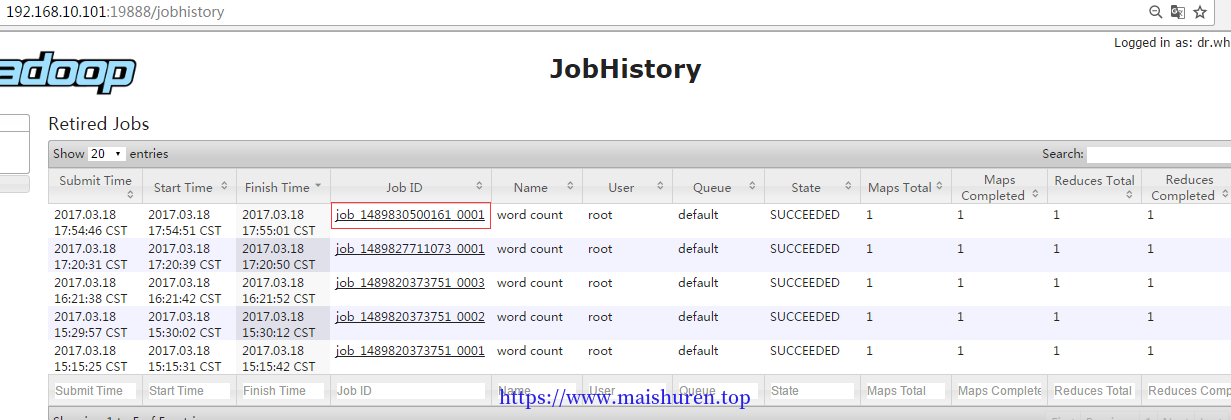
job运行情况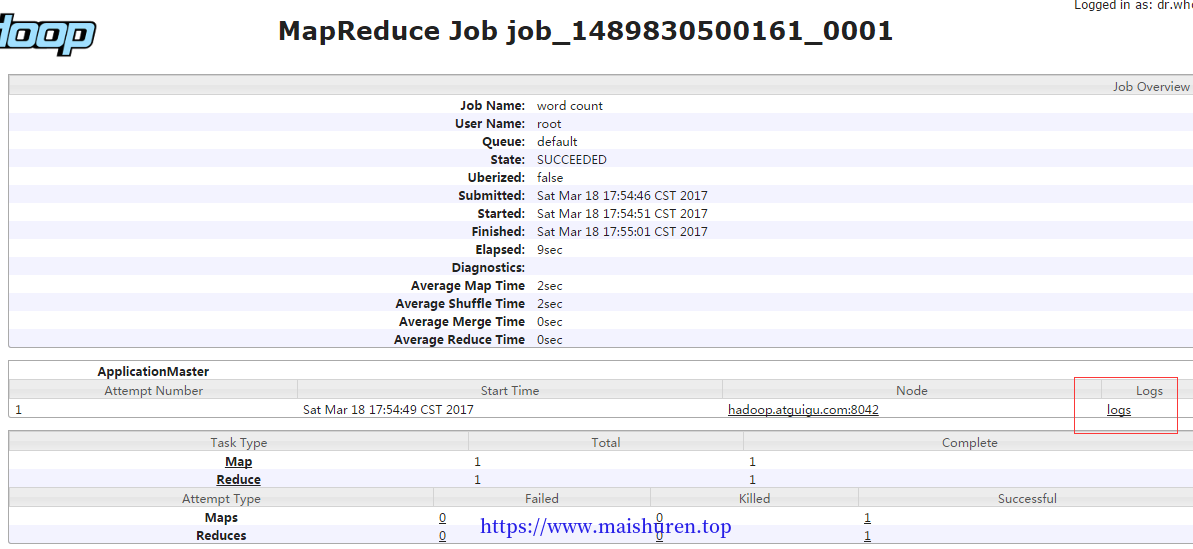
查看日志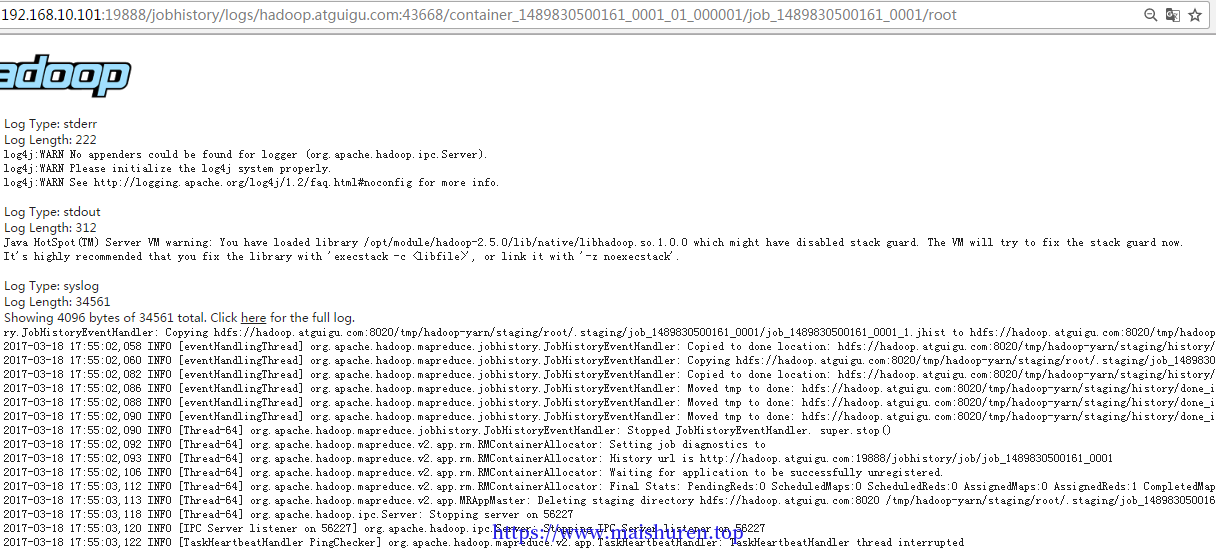
配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
(1)默认配置文件:
| 要获取的默认文件 |
文件存放在Hadoop的jar包中的位置 |
| core-default.xml |
hadoop-common-2.7.2.jar/ core-default.xml |
| hdfs-default.xml |
hadoop-hdfs-2.7.2.jar/ hdfs-default.xml |
| yarn-default.xml |
hadoop-yarn-common-2.7.2.jar/ yarn-default.xml |
| mapred-default.xml |
hadoop-mapreduce-client-core-2.7.2.jar/ mapred-default.xml |
(2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
完全分布式运行模式
编写集群分发脚本
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
rsync语法:
1
2
|
rsync -av $pdir/$fname $user@host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
|
通过vim编写xsync:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if ((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=1; host<4; host++)); do
echo ------------------- hadoop$host --------------
rsync -av $pdir/$fname $user@hadoop$host:$pdir
done
|
修改权限:
1
|
[root@centos7 bigdata]$ chmod 777 xsync
|
测试:
1
|
[root@centos7 bigdata]$ mv xsync /usr/local/bin/
|
如果报错:rsync: command not found,需要安装rsync
集群配置
- 集群规划
|
hadoop1 |
hadoop2 |
hadoop3 |
| HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
-
修改配置文件
- 核心配置文件:core-site.xml
1
2
3
4
5
6
7
8
9
10
11
|
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/software/bigdata/hadoop/data/tmp</value>
</property>
|
2) HDFS配置文件
hadoop-env.sh
1
2
|
# 配置jdk所在的目录
export JAVA_HOME=/opt/software/bigdata/jdk1.8
|
hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
|
<!--指定hdfs的副本数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置:SecondaryNameNode -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop3:50090</value>
</property>
|
3) yarn配置文件
yarn-env.sh
1
2
|
# 配置jdk所在的目录
export JAVA_HOME=/opt/software/bigdata/jdk1.8
|
yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
|
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop2</value>
</property>
|
4) MapperReducer配置文件
mapred-env.sh
1
2
|
# 配置jdk所在的目录
export JAVA_HOME=/opt/software/bigdata/jdk1.8
|
mapred-site.xml
1
2
3
4
5
6
7
8
9
|
#根据模板修改
cp mapred-site.xml.template mapred-site.xml
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
|
- 修改完成后,通过集群分发脚本分发到各个服务器上
1
|
[root@hadoop1 bigdata]$ xsync /opt/software/bigdata/hadoop/
|
- 在配置了NameNode的服务器上格式化集群
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
[root@hadoop1 bigdata]$ hdfs namenode -format
#出现一下一大堆的配置信息
[root@msr-server hadoop]# hdfs namenode -format
20/06/25 10:00:04 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = msr-server/192.168.74.129
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.2
STARTUP_MSG: classpath = /opt/software/bigdata/hadoop/etc/hadoop:/opt/software/bigdata/hadoop/share/hadoop/common/lib/commons-io-2.4.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/commons-lang-2.6.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/mockito-all-1.8.5.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/commons-digester-1.8.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/servlet-api-2.5.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/slf4j-api-1.7.10.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/hamcrest-core-1.3.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/log4j-1.2.17.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/gson-2.2.4.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/commons-logging-1.1.3.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/commons-cli-1.2.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/commons-collections-3.2.2.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/asm-3.2.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/xz-1.0.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/jersey-server-1.9.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/jersey-core-1.9.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/paranamer-2.3.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/commons-codec-1.4.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/httpclient-4.2.5.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/jettison-1.1.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/jetty-util-6.1.26.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/activation-1.1.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/zookeeper-3.4.6.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/jets3t-0.9.0.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/commons-configuration-1.6.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/junit-4.11.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/jsp-api-2.1.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/guava-11.0.2.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/avro-1.7.4.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/jsr305-3.0.0.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/jsch-0.1.42.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/commons-httpclient-3.1.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/jetty-6.1.26.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/curator-framework-2.7.1.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/jersey-json-1.9.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/netty-3.6.2.Final.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/curator-client-2.7.1.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/stax-api-1.0-2.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/commons-compress-1.4.1.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/xmlenc-0.52.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/commons-math3-3.1.1.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/httpcore-4.2.5.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/hadoop-annotations-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/commons-net-3.1.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/curator-recipes-2.7.1.jar:/opt/software/bigdata/hadoop/share/hadoop/common/lib/hadoop-auth-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/common/hadoop-nfs-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/common/hadoop-common-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/common/hadoop-common-2.7.2-tests.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/commons-io-2.4.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/xercesImpl-2.9.1.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/xml-apis-1.3.04.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/htrace-core-3.1.0-incubating.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/asm-3.2.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/guava-11.0.2.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/jsr305-3.0.0.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/lib/netty-all-4.0.23.Final.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/hadoop-hdfs-nfs-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/hadoop-hdfs-2.7.2-tests.jar:/opt/software/bigdata/hadoop/share/hadoop/hdfs/hadoop-hdfs-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/commons-io-2.4.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/commons-lang-2.6.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/servlet-api-2.5.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/log4j-1.2.17.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/commons-cli-1.2.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/guice-3.0.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/commons-collections-3.2.2.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/asm-3.2.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/jersey-client-1.9.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/xz-1.0.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/jersey-server-1.9.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/jersey-core-1.9.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/commons-codec-1.4.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/jettison-1.1.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/activation-1.1.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/zookeeper-3.4.6.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/aopalliance-1.0.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/guava-11.0.2.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/jsr305-3.0.0.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/javax.inject-1.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/jetty-6.1.26.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/jersey-json-1.9.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/netty-3.6.2.Final.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/zookeeper-3.4.6-tests.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/hadoop-yarn-server-tests-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/hadoop-yarn-server-common-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/hadoop-yarn-api-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/hadoop-yarn-common-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/hadoop-yarn-registry-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/yarn/hadoop-yarn-client-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/guice-3.0.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/asm-3.2.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/xz-1.0.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/junit-4.11.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/javax.inject-1.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/lib/hadoop-annotations-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.2-tests.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.2.jar:/opt/software/bigdata/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.7.2.jar:/opt/software/bigdata/hadoop/contrib/capacity-scheduler/*.jar
STARTUP_MSG: build = Unknown -r Unknown; compiled by 'root' on 2017-05-22T10:49Z
STARTUP_MSG: java = 1.8.0_211
************************************************************/
20/06/25 10:00:04 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
20/06/25 10:00:04 INFO namenode.NameNode: createNameNode [-format]
Formatting using clusterid: CID-8530cbf5-a4b6-454b-bfdb-2c8a016d55a7
20/06/25 10:00:05 INFO namenode.FSNamesystem: No KeyProvider found.
20/06/25 10:00:05 INFO namenode.FSNamesystem: fsLock is fair:true
20/06/25 10:00:06 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000
20/06/25 10:00:06 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
20/06/25 10:00:06 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000
20/06/25 10:00:06 INFO blockmanagement.BlockManager: The block deletion will start around 2020 Jun 25 10:00:06
20/06/25 10:00:06 INFO util.GSet: Computing capacity for map BlocksMap
20/06/25 10:00:06 INFO util.GSet: VM type = 64-bit
20/06/25 10:00:06 INFO util.GSet: 2.0% max memory 966.7 MB = 19.3 MB
20/06/25 10:00:06 INFO util.GSet: capacity = 2^21 = 2097152 entries
20/06/25 10:00:06 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false
20/06/25 10:00:06 INFO blockmanagement.BlockManager: defaultReplication = 3
20/06/25 10:00:06 INFO blockmanagement.BlockManager: maxReplication = 512
20/06/25 10:00:06 INFO blockmanagement.BlockManager: minReplication = 1
20/06/25 10:00:06 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
20/06/25 10:00:06 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000
20/06/25 10:00:06 INFO blockmanagement.BlockManager: encryptDataTransfer = false
20/06/25 10:00:06 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
20/06/25 10:00:06 INFO namenode.FSNamesystem: fsOwner = root (auth:SIMPLE)
20/06/25 10:00:06 INFO namenode.FSNamesystem: supergroup = supergroup
20/06/25 10:00:06 INFO namenode.FSNamesystem: isPermissionEnabled = true
20/06/25 10:00:06 INFO namenode.FSNamesystem: HA Enabled: false
20/06/25 10:00:06 INFO namenode.FSNamesystem: Append Enabled: true
20/06/25 10:00:06 INFO util.GSet: Computing capacity for map INodeMap
20/06/25 10:00:06 INFO util.GSet: VM type = 64-bit
20/06/25 10:00:06 INFO util.GSet: 1.0% max memory 966.7 MB = 9.7 MB
20/06/25 10:00:06 INFO util.GSet: capacity = 2^20 = 1048576 entries
20/06/25 10:00:06 INFO namenode.FSDirectory: ACLs enabled? false
20/06/25 10:00:06 INFO namenode.FSDirectory: XAttrs enabled? true
20/06/25 10:00:06 INFO namenode.FSDirectory: Maximum size of an xattr: 16384
20/06/25 10:00:06 INFO namenode.NameNode: Caching file names occuring more than 10 times
20/06/25 10:00:06 INFO util.GSet: Computing capacity for map cachedBlocks
20/06/25 10:00:06 INFO util.GSet: VM type = 64-bit
20/06/25 10:00:06 INFO util.GSet: 0.25% max memory 966.7 MB = 2.4 MB
20/06/25 10:00:06 INFO util.GSet: capacity = 2^18 = 262144 entries
20/06/25 10:00:06 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
20/06/25 10:00:06 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
20/06/25 10:00:06 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
20/06/25 10:00:06 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
20/06/25 10:00:06 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
20/06/25 10:00:06 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
20/06/25 10:00:06 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
20/06/25 10:00:06 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
20/06/25 10:00:06 INFO util.GSet: Computing capacity for map NameNodeRetryCache
20/06/25 10:00:06 INFO util.GSet: VM type = 64-bit
20/06/25 10:00:06 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB
20/06/25 10:00:06 INFO util.GSet: capacity = 2^15 = 32768 entries
20/06/25 10:00:07 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1479747258-172.16.198.170-1593050406999
20/06/25 10:00:07 INFO common.Storage: Storage directory /opt/software/bigdata/hadoop/data/tmp/dfs/name has been successfully formatted.
20/06/25 10:00:07 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
20/06/25 10:00:07 INFO util.ExitUtil: Exiting with status 0
20/06/25 10:00:07 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at msr-server/192.168.74.129
************************************************************/
|
注:如果使用云服务器配置,在编写hosts文件的时候,是以ip hostname来配置,在hadoop1主机上配置是ip必须为服务器的内网地址,其他的服务器同理。
1
2
3
|
xxx.79 hadoop1
xxx.58 hadoop2
xxx.47 hadoop3
|
配置ssh免密码登录
1
2
3
4
|
[root@hadoop1 .ssh]$ ssh-keygen -t rsa
[root@hadoop1 .ssh]$ ssh-copy-id hadoop1
[root@hadoop1 .ssh]$ ssh-copy-id hadoop2
[root@hadoop1 .ssh]$ ssh-copy-id hadoop3
|
集群内的三台服务器都需要这样配置一下。
群起集群配置
配置slaves:/opt/software/hadoop/etc/hadoop/slaves,通过xsync发送的其他服务器上。
1
2
3
|
hadoop1
hadoop2
hadoop3
|
启动测试
在第一次启动的时候必须,先格式化namenode服务器(如果在格式化的过程中失败,重新再次格式化namenode的时候,先删除logs和data文件夹,再去格式化)
1
|
[root@hadoop1 hadoop]$ bin/hdfs namenode -format
|
群起hdfs
1
|
[root@hadoop1 hadoop]$ start-dfs.sh
|
群起yarn,因为yarn的resourcemanager是配置在hadoop2上,所以在hadoop2的服务器上执行
1
|
[root@hadoop2 hadoop]$ start-yarn.sh
|